안녕하세요.
이번에 인공지능협회에서 인공지능 온라인 무료 교육이 있어 수강한 내용을 간략하게 내용 정리 및 후기를 공유합니다.
실제 강의제목은 “스마트 공장을 위한 제조 지능화 혁신과 AI 빅데이터”입니다. 두꺼운 교재를 며칠 전에 택배로 전달해 줍니다. 책 두께를 보고 이틀 안에 가능할지 생각부터 들었습니다.
그러나 결론적으로 말하자면 가능은 했습니다. PPT 1페이지 단위로 인쇄되어 있고 결과도 한 페이지씩 캡처되어 있어 빠르게 넘어갑니다.
강사님이 반도체 분야에 계셨던 분이라서 그쪽 분야에서 제조 데이터 분석 내용 중심으로 설명해 주었습니다. 그리고 아래 내용은 전체 내용 요약이라기보다는 목차로 생각하셔서 이렇게 되는구나 생각하시고 보시면 어떨까 합니다.
<1> 1일 차 오전 교육 내용
1. 들어가기 내용
1) 반도체 산업에 특성 및 간단한 공정 설명
2) 제조 지능화가 필요성, 추진화 단계
- 종이 작성은 최소화 및 설비 On-Line화 (데이터 누적)
- 제조 지능화에 대해서 상세 설명
- 추가 내용
https://www.youtube.com/watch?v=fYQF4zoWoxE
2. 혁신 사례들 설명
- 반도체 생산을 관점으로 머신러닝을 적용사례 설명
- 웨이퍼 검사할 때 비정상 시그널을 통해서 에러 분석하는 방법 간단히 설명
- 데이터 수집하는 것이 중요하고 그것을 인사이트로 뽑아내는 것이 중요
- 제조에 있어서 적용한 사례 설명과 강사분의 논문에 대한 설명
- Cloud에서 모든 처리를 다하기는 많은 비용 발생으로 데이터 소스(IoT) 근처에 있는 Edge에서 Raw를 처리 후 Cloud에 보낸 후 Cloud에서는 받은 정보를 다시 최적화시켜 그것을 다시 Edge로 보내어 주는 형태로 전환되는 추세
<2> 1일 차 오전 교육 내용
1. Digital Twin
- Factory Architecture 구성에 대해서 IoT Platform, MES, EES, BI, Data Analytics 간략한 개념 설명
- 공장에서 데이터로 받을 수 있는 항목들, 그리고 설비상에서 고장 혹은 사고가 날 수 있는 데이터를 확인시켜 주고, 원인을 분석 및 감지할 수 있는 부분 사례로 설명(Digital Twin), 설비 시뮬레이션 동영상 시청
2. Homework 내용 설명
- AI 혁신 문제 정의 및 혁신 모델 기술서 양식을 보고 현재 있는 제조 현장에서 AI로 변경 가능하다고 예상하는 것을 작성해 보기
3. 프로그램 설치
- 강의 시작 전에 PC에 아나콘다 프로그램을 설치하라고 사전 줌 회의로 진행했습니다. 추가적으로 Anaconda.navigator 보면 Orange 설치해야 합니다.
4. Anaconda 사용법 확인
- Anaconda.navigator를 실행해서 Orange 3 Install 합니다.
- 아나콘다 내비게이션(Anaconda.navigator) 3.26 버전으로 실행해서 add-ons 설치하면 에러가 나서
https://orangedatamining.com/download/#windows 별도로의 3.32 버전을 받아서 설치하면 add-on 설치됨
- 옵션을 선택해서 설치해 줍니다.
“Options” -> “Add-ons” 추가 선택= associate, ImageAnalytics, Text, Timeseries

5. Orange3 실습하기
1) 일산화탄소 및 습도 반도체 업체의 가스 센서 어레이 데이터로 실습
2) Wafer Defect Map Data Sets에 대한 실습 - 웨이퍼 불량 이미지를 확인

3) 패널에 흠집난 이미지 확인

4) 데이터 시각화
- 데이터를 어떻게 보이게 할지 시각화 모듈 실습 (Box Plot, Scatter Plot, Sleve Diagram... )
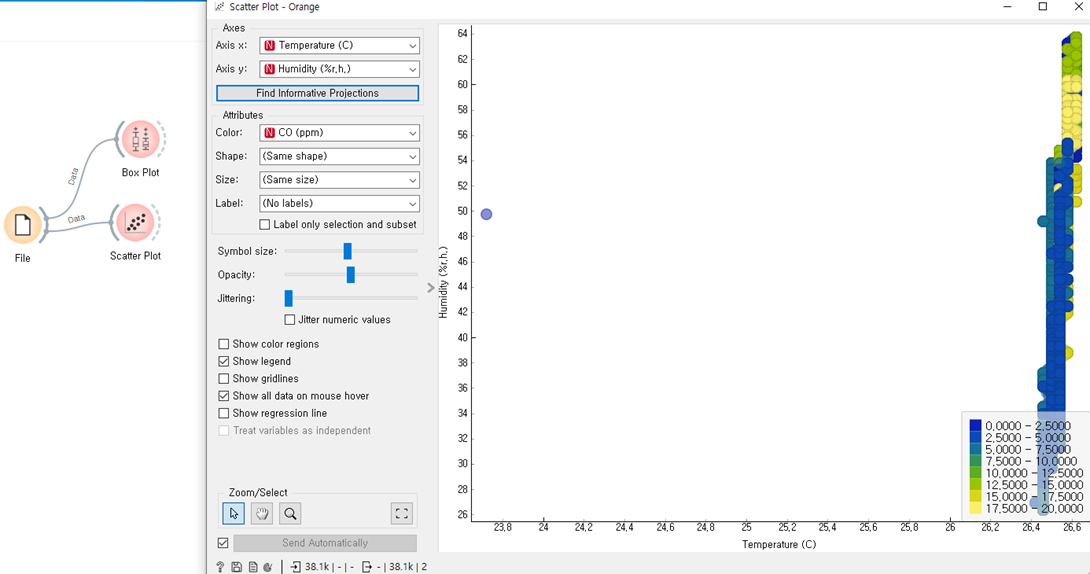
5) 전처리를 이용한 데이터 처리
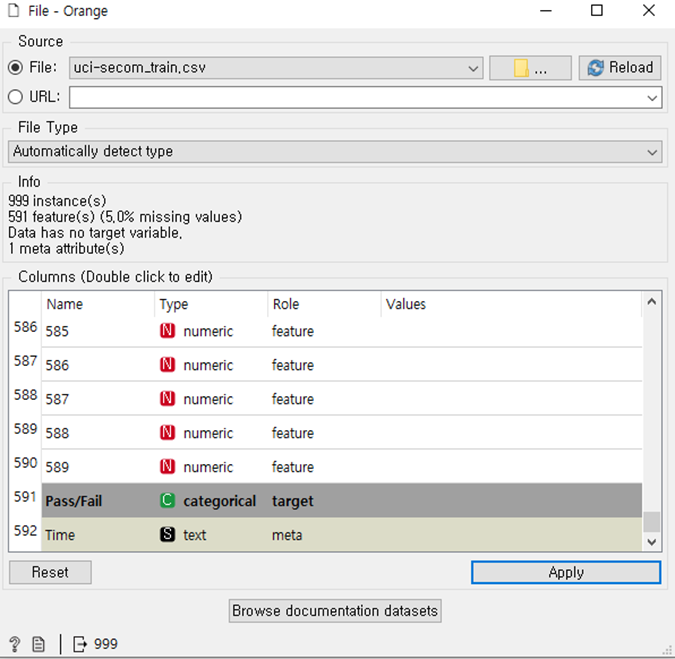
- 센서 데이터를 이용해서 preprocess를 이용해서 590 개정도의 항목에서 10개의 항목으로 줄이는 전처리를 통해 데
이터를 처리
- 파일을 읽어올 때 마지막 부분에 Role 부분에 Target으로 설정 맞춰 주어야 Test and Score 값을 볼 수 있음
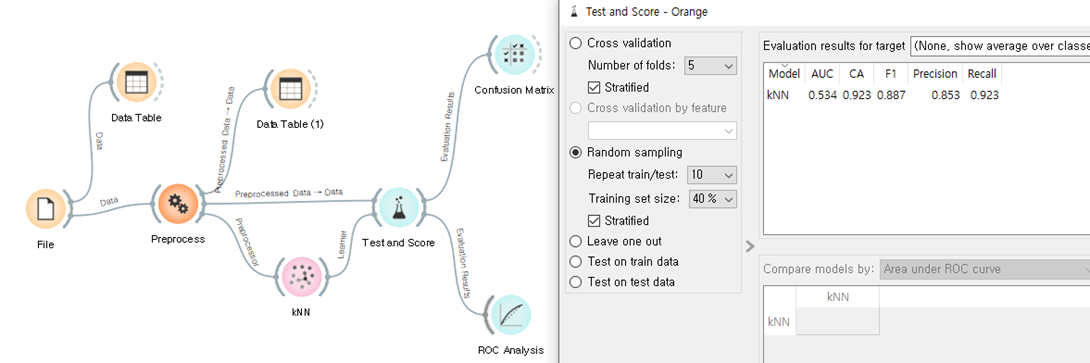
- kNN을 이용해서 나오는 트레인 사이즈와 반복 횟수를 변경해 가며 스코어를 확인 가능
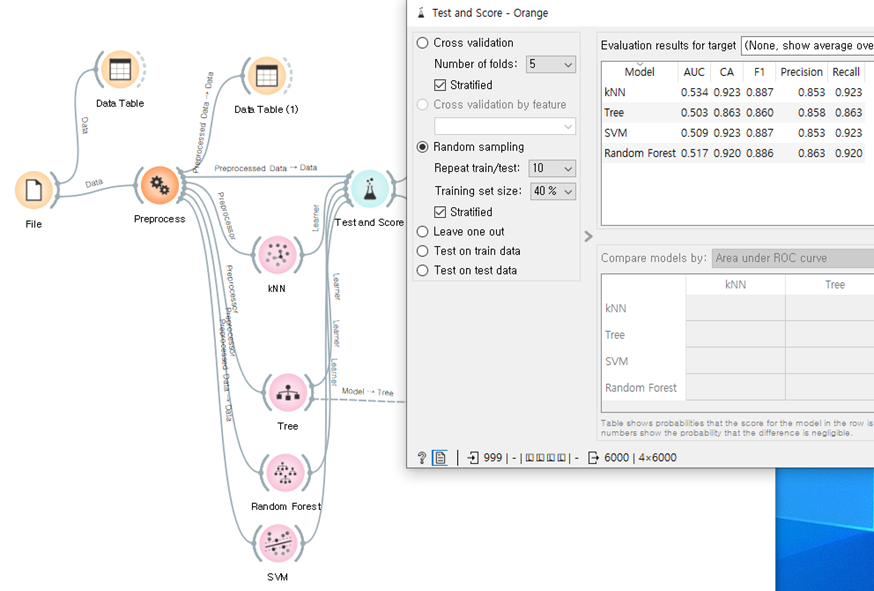
6. 지도학습-분류(Classification)
1) k-NN
- 특정 포인트에서 가장 가까운 K 개의 이웃 포인터들을 참조하여 그 포인트의 출력 변수 Y를 예측하는 알고리즘 / 학습과정이 없다. /추론 과정만 있다. / 유사도 계산 세타 값과 작을수록 유사한 값
- k-값이 너무 작을 경우 정확도가 너무 낮음, k 값이 너무 크면 너무 느려짐, 적당한 값을 선택하는 것이 필요
2) Recall vs Precision
- True와 False가 서로 불균형하게 있는 경우에 어떻게 성능 평가하기 위해서, Precision과 Recall을 이용해야 한다.
- 사용한 알고리즘을 통해서 Positive라고 예측한 것들 중에서 얼마나 정답을 잘 맞혔는지의 비율을 Precision
예) 내가 양성이라고 판단한 게 얼마나 맞추었나? 양성 진단 정확성 : TP / (TP + FP)
- 본래 내가 가진 실제 Positive 중에서 얼마나 내 알고리즘이 진짜를 잘 찾았는지의 비율을 Recall
예) 전체 양성 중 내가 얼마 찾아냈나? 양성 탐색 효과 : TP/(FP + FN)
- 숫자만 좋다고 좋은 것이 아니라 도메인마다 선택하는 것이 중요하다 / 분석가가 잘 판단해서 잘 내려야 함.
3) Decision Tree (의사결정 나무)
예시) 포유류 분류, 채무불이행자 분류로 개념 설명
4) 랜덤 포레스트
- 트리구조를 여러 개로 묶음
5) Support Vector Machine
- Linear SVMs
6) 나이브 베이지 분류
- 수많은 여치와 메뚜기의 몸체 길이와 더듬이 길이를 데이터로 입력 후 데이터 분포로 여치와 메뚜기를 하는 방법
7) 베이지 정리
- 뇌막염 걸린 사람 중에 류머티즘 환자가 50%이다. / 이름으로 성별 예상하기 (확률적 계산)
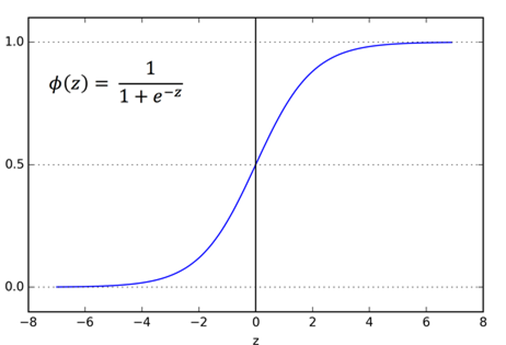
- Logistic regression 모델은 예측 모델이 아니라, 분류 모델이다. Logistic function 중요 0~1 값으로 나옴
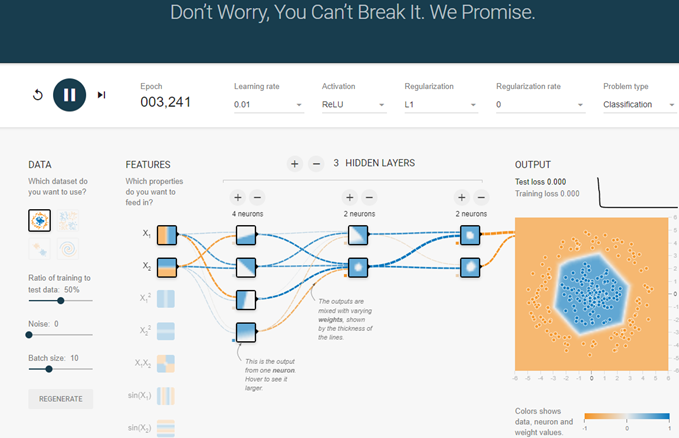
8) Neural Network 웹상에서 확인
- Sigmoid Activation Function 설명
- 주항 색 동그라미와 하늘색 동그라미 데이터가 Layer 등 어떻게 하느냐에 따라 분류가 어떻게 되는 것을 확인해 볼 수 있다. https://playground.tensorflow.org/
9) Regularization
- 학습 데이터에 과적합(overfitting) 하는 것을 방지
- L1 : 입력 변수 계수 중 일부를 0에 매우 가깝게 만들어 중요한 입력 변수를 선택하는 효과가 있음(sparse Modeling)
- L2 : 경계면을 날카롭지 않게 하는 역할
<3> 1일 차 전반적인 소감
- 반도체 제조 현장에 대해서 설명과 에러가 발생하는 원인을 찾고 수율을 높일 수 있는 사례를 이론적으로 설명해 줍니다. 즉, 개발자 관점보다는 관리자 관점에서 반도체 및 AI 데이터 분석한다는 느낌입니다.
- 머신러닝 모델 수도 많고 이것을 공식적으로 풀이하는 것도 쉽지 않기 때문에 상세한 설명은 부족하였습니다. 그러나 빠르게 분류해서 이해하고 툴을 이용하면서 이렇게 데이터 사용할 수 있겠구나 설명을 들으면 좋겠다고 생각 들었습니다.
- 실제 코딩은 없다 보니 AI 머신러닝 코딩을 배우려고 하는 사람은 한 번쯤 생각이 필요합니다.
<참고 사이트>
1. [머신러닝] Precison과 Recall 이란? (F-measure / Precision-Recall Curve / AUC-PR 개념 포함!)
https://m.blog.naver.com/sw4r/221681933731
2. Activation Functions in Neural Networks
https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6
'Artificial Intelligence > basic' 카테고리의 다른 글
| [교육후기] OpenCV와 Tensorflow Lite를 활용한 라즈베리 파이 지능형 비전 서비스 개발 - 1일 차 (2) | 2025.02.22 |
|---|---|
| [5분 AI] 머신러닝 학습 방법 4가지 (0) | 2024.08.17 |
| 인공지능 미래산업 활용 무료교육 후기 (2일 차) (0) | 2024.04.14 |
| 인공지능 미래산업 활용 무료교육 후기 (1일 차 - 오후) (0) | 2024.04.09 |
| 인공지능 미래산업 활용 무료교육 후기 (1일 차 - 오전) (0) | 2024.04.05 |