안녕하세요.
이전 수업내용에 이어서 오후에도 머신러닝 학습방법에 대해서 이론적인 설명과 동영상 예시와 무료 웹을 인공지능에 대해서 실습해 볼 수 있었습니다.
1. 4교시(머신러닝 학습 상세, AI 필터)
1) 분류 : 사진이라는 문제와 강아지라는 해답을 넣어서 강아지라는 규칙을 만들어 낸 후 강아지 사진을 찾아낸 것을 확인한다.
2) 예측 : A 소비자가 우유와 샌드위치를 구매하고 B는 우유만 구매한 데이터를 가지고 컴퓨터 어떤 것을 추천하겠는가 라는 질문을 하고 어떤 것이 필요한지 제시한다.
- 과거 데이터를 기반으로 분석하여 다음 데이터를 알려주는 방식
3) autodraw 사이트 소개 :
임의로 그린 그림을 판단해서 잘 그려진 그림으로 변환 가능. 회원가입 불필요
4) Quick, Draw 사이트 소개 :
- 정답(그려야 할 것)을 주고 사용자에게 그림을 그리게 해서 신경망이 맞추게 하면 되는 게임. 결국 우리가 그림 그려서 학습 데이터로 사용한다. 예, 선풍기를 그려보라고 문제로 해서 인식되면 구글 데이터로 저장한다. 실시간으로 분석하면서 어떤 것인지 예측하면서 음성으로 안내해 준다. 회원가입 불필요
https://quickdraw.withgoogle.com/
- 구글 알파고(나우 캐스팅)를 이용해서 영국 날씨 예측에 사용하고 있다. 옛날 기상 상태 위성사진을 가지고 학습시킨 후 일기예보를 한다. 그리고 최신 데이터로 검증할 수 있다. 기존의 방식은 수치예보방식으로 수학공식을 사용하고 있다. (온도, 습도, 기압 등 입력 데이터로 넣고 슈퍼컴퓨터가 계산해서 예측한다)
http://www.aitimes.com/news/articleView.html?idxno=140843
2. 5교시(딥러닝 구조, 인공신경, GAN)
1) 딥러닝 구조
- 사람의 뉴런 구조를 본떠서 만든 것이 초기 퍼셉트론의 구조
-- 입력값 – 가중치(학습) - 전체합 – 0과 1 사이로 나오는 값으로 출력함

-- 딥러닝을 표현하는 방식을 보면 작은 하나가 퍼셉트론이고 단계별로 묶어서 은닉 계층을 형성한다.

출처 : https://wikidocs.net/24958
2) 딥러닝 종류 (ANN, DNN, CNN, RNN)
(1) ANN : 사람의 신경망 원리와 구조를 모방하여 만든 기계 학습 알고리즘
(2) DNN : 모델 내 은닉층을 많이 늘려서 학습의 결과를 향상하는 알고리즘
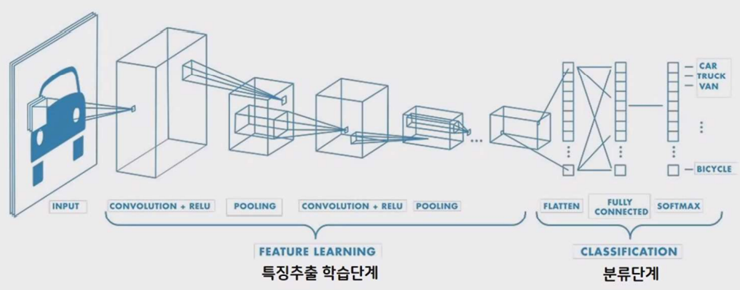
(3) CNN(합성곱 신경망) : 기존 방식은 데이터에서 지식을 추출해 학습이 이루어졌지만, CNN은 데이터의 특징을 추출하여 특징의 패턴을 파악하는 구조
- 원본 이미지에 순차적(0,0~)으로 읽어 내려가면서 필터 블록을 곱하고 더해가면서 새로운 이미지를 만들어간다.
- Convolution(필터 사용) -> Pooling(압축)->Convolution(더 복잡한 필터 사용)->Pooling->Fully Connected...(특성 지도가 만들어짐)... Fully Connected -> Output predictions

(4) RNN(순환 신경망) : 반복적이고 순차적인 데이터(Sequential data) 학습에 특화된 인공신경망의 한 종류로서 내부의 순호나 구조가 들어있다는 특징 (음성 그래프 학습, 번역, 주식 차트 분석 추천 프로그램)
3) Autonomous Racing :
AMZ Driverless with fluela과 영상 시청
https://www.youtube.com/watch?v=FbKLE7uar9Y
4) GAN 기술 소개 - 인공지능이 가상의 사람 얼굴을 만들어 내고(GAN 기술을 이용해서 만들어 냄) 어떤 사진이 진짜 얼굴이고 생성된 얼굴인지 맞춰보는 사이트 소개
http://www.whichfaceisreal.com/index.php
5) GAN (Generative Adversarial network, 생성적 적대 신경망)
- 심층학습의 기법을 이용해 가짜를 만드는 네트워크와 가짜를 거르는 네트워크를 경쟁적으로 훈련시켜서 가짜를 만드는 방법을 훈련시키는 네트워크이며, 2가지 모델(생성 모델, 판별 모델)을 동시에 사용한다.
예) 사람 얼굴만 학습한 판별 모델과 가짜 얼굴을 생성하는 모델을 만들어 생성한 얼굴을 판별 모델로 판별을 받고 실패도 학습하여 성공을 위해 학습해 나간다.
(1) Cycle GAN : 말(horse) 이미지에서 얼룩말(Zebra) 이미지의 특징을 씌우는 방식
(2) SRGAN : 합성 이미지를 저해상도로 만들어서 고해상도로 다시 진짜 이미지처럼 만듦
(3) Stack GAN : 문자 설명을 가지고 이미지를 만들어 냄.(새를 문자로 설명하고 가짜 새를 만들어냄)
(4) Beauty GAN : 얼굴 부위를 세그먼테이션 해서 따내고, 다른 이미지로 붙여 넣음
(원본 무화장 얼굴 + 화장한 얼굴 = 무화장 얼굴을 화장하게 만듦)
6) Generated photos (가상 인물을 만들 수 있다) 사이트 소개
3. 6교시 (빅데이터, 객체 탐지 방법)
1) 빅데이터
-- 데이터 단위 : 1Byte – 1KB – 1MB – 1GB – 1TB – 1PB – 1EB - 1ZB
-- 하드웨어 : CPU(순차적 명령 처리), GPU(대규모 병렬 처리 계산기)
-- 빅데이터 : 클라우드 시스템
-- 알고리즘 : Deep Learning Neural Network
-- DIKW 피라미드 : Data를 끌어내애서 정보(Information)-> 지식(Knowledge)-> 현실, 활용(Wisdom)으로 만들어 낸다.
-- 데이터의 종류
(1) 정형 : 고정된 필드에 저장된 데이터
(2) 반정형 : 고정된 필드에 저장되어 있지는 않지만, 메타데이터나 스키마 등을 포함하는 데이터
(3) 비정형 : 고정된 필드에 저장되어 있지 않는 데이터
2) 빅데이터란,
- 기존 데이터베이스 관리 도구의 능력을 넘어서는 대량(수십 테라 바이트)의 정형 또는 심지어 데이터베이스 형태가 아닌 비정형의 데이터 집합조차 포함한 데이터로부터 가치를 추출하고 결과를 분석하는 기술(수집-> 저장-> 분석-> 처리하기 어려울 정도로 방대한 양의 데이터를 의미
(Volume, Variety, Velocity 3V + Veracity, Value, Visualization 3V = 6V + Volatility 1V = 7V)

출처 - https://www.ibmbigdatahub.com/infographic/four-vs-big-data
3) 인공지능(AI)은 잘 만들어진 데이터가 필요하고 AI 프로젝트에 소요되는 시간 비율을 보면 데이터 수집 10%, 데이터 정제 25%, 데이터 라벨링 25%, 알고리즘 개발 3% 정도 등 소요시간이 필요하다. 다르게 이야기하면 AI 알고리즘 개발 시간보다 데이터를 정제하고 라벨링 하는데 많은 시간이 걸린다.

4) 많은 양의 학습 데이터가 필요한 이유
- 텐서플로우(TensorFlow) 튜토리얼에서 의류 이미지 분류자료를 보면 옷과 신발을 70,000개 데이터에서 60,000개는 네트워크 훈련용으로 10,000개는 검증용으로 사용한다. 보통 8대 2 비유로 데이터를 나누어 학습용(8), 검증(2)으로 사용한다. 학습시켜서 나온 정확도가 0.89로 정확도 89% 나옴. Epoch는 60,000개를 한번 학습(트레이닝 셋이 신경망을 통과한 횟수)한 횟수를 의미
https://www.tensorflow.org/tutorials/keras/classification?hl=ko

출처 : 패션-MNIST 샘플 (Zalando, MIT License)
5) 데이터 활용사례
- Walmart : 데이터 마이닝으로 기저귀와 맥주 관계를 알아냄
- amazon : 페르소나(persona, 어떤 제품 혹은 서비스를 사용할 만한 목표 인구 집단 안에 있는 다양한 사용자 유형들을 대표하는 가상의 인물)를 만들어 마케팅 전략 수립을 위한 자료로 이용
- google : Flu Trends, 감기 발생과 감기 검색과 연관 관계를 가지고 지도 분포를 만들어 냈지만 실패
- 오리온 : 김치찌개 먹는 사람이 스윙칩을 먹더라 해서 김치찌개 맛 스윙칩 만듦 그러나 실패
6) 구글의 음성 대화 동영상 확인, 구글 듀플렉스
7) 인공지능의 객체 탐지방법의 이해
(1) 인공지능이 객체 탐지(Object Detection) 하는 방법
- Single Object : Classification + Localization(바운딩 박스로 표시)
- Multiple Objects : Object Dectection + Instance Segmentation(경계면을 따냄)
(2) 데이터 라벨링의 종류
Bounding Boxes, Image Segmentation, Tagging of Image Elements, Face Marking with Points
(표정까지 잡기 위해서는 68개의 점을 찍어서 사용한다, 5개의 점으로 얼굴만 인식할 때 사용할 수 있다.)
8) YOLO vs SSD 비교
- 객체 탐지 대표 엔진 - Bounding Boxes 딥러닝 학습을 통한 결과 youtube 영상 확인
https://www.youtube.com/watch?v=n_LL_j28WL4
9) Image Segmentation 딥러닝 학습을 통한 결과 youtube 영상 확인
(Mask R-CNN – Object Detection, Segmentation)
4. 7교시 (티처블머신 사용법, CNN 원리 이해)
1) 티처블머신 사용법
- 클라우드 기반 인공지능 학습시킬 수 있도록 제작된 웹 기반 도구
- 이미지 인식, 사운드 인식, 자세 학습 가능
-- 이미지 학습 -> 클래스 3개의 이미지(문제)를 만든 뒤 가습기, 스마트폰, 물병 이름(해답)을 주고 학습 진행

2) AI 이미지 인식 원리 이해 (CNN)
이미지에서 필터를 가지고 이미지의 특징 패턴을 찾아낸다.
(1) CNN(합성곱 신경망) 설명
- 빛의 3요소 (RGB, Red, Green, Blue) 컴퓨터는 빛으로 들어오면 3가지 채널로 바꾼다.
- 특성 지도를 만들어 내고 풀링(압축)하고 분류함
--풀링(Pooling)은 주로 Max pooling을 사용한다. Average pooling도 있지만 평균 내기 위한 시간이 걸리기 때문에 속도면에서 Max pooling을 사용한다.
-- 평탄화 작업(특징 추출한 데이터를 배열화하여 특성화 지도로 이미지 간 비교하기가 쉬워진다.
3) CNN실습
- 5*5표에 삼각형을 그려 넣고, 2*2 필터를 넣어 특성 지도를 만들고, 폴링 한 후 평탄화 작업을 해보는 것을 실습한다. 어떤 특징 가진 필터를 사용할 것인지에 따라 특성 지도는 여러 개가 있을 수 있다.
- 원본 이미지와 특성을 가지는 필터 선정한다.

- 원본 이미지에 필터를 겹쳐가며 특성 지도 한 칸의 값을 생성한다. 그리고 특성 지도에서 큰 값을 기준으로 해서 작은 특성화 지도를 만들어 낼 수 있다. 이것을 평탄화(직렬화)시키면 분류기의 역할이 된다.

감사합니다.
'Artificial Intelligence > basic' 카테고리의 다른 글
| [교육후기] OpenCV와 Tensorflow Lite를 활용한 라즈베리 파이 지능형 비전 서비스 개발 - 1일 차 (2) | 2025.02.22 |
|---|---|
| [5분 AI] 머신러닝 학습 방법 4가지 (0) | 2024.08.17 |
| 인공지능 스마트 팩토리 교육 2일 교육 중 1일 차 후기 (0) | 2024.04.23 |
| 인공지능 미래산업 활용 무료교육 후기 (2일 차) (0) | 2024.04.14 |
| 인공지능 미래산업 활용 무료교육 후기 (1일 차 - 오전) (0) | 2024.04.05 |